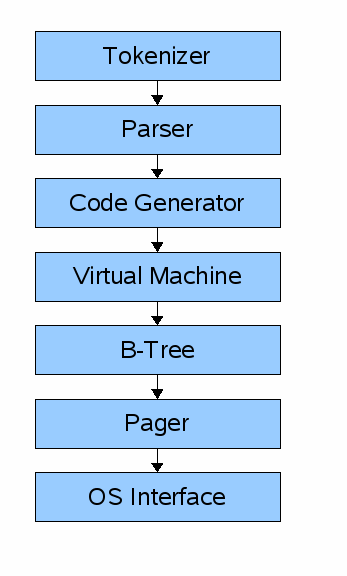
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
| @@ -2,6 +2,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
+#include <stdint.h>
typedef struct {
char* buffer;
@@ -10,6 +11,105 @@ typedef struct {
} InputBuffer;
+typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
+
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum {
+ PREPARE_SUCCESS,
+ PREPARE_SYNTAX_ERROR,
+ PREPARE_UNRECOGNIZED_STATEMENT
+ } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
+typedef struct {
+ StatementType type;
+ Row row_to_insert;
+} Statement;
+
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
+
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
+
+void print_row(Row* row) {
+ printf("(%d, %s, %s)\n", row->id, row->username, row->email);
+}
+
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void *source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
+
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = table->pages[page_num];
+ if (page == NULL) {
+
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+Table* new_table() {
+ Table* table = malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +140,105 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ free_table(table);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email
+ );
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table *table) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ return execute_insert(statement, table);
+ case (STATEMENT_SELECT):
+ return execute_select(statement, table);
+ }
+}
+
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer, table)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
+ }
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
}
}
}
|